

Machine learning (ML) is a branch of artificial intelligence (AI) and computer science that focuses on the using data and algorithms to enable AI to imitate the way that humans learn, gradually improving its accuracy.
How does machine learning work?
- A Decision Process: In general, machine learning algorithms are used to make a prediction or classification. Based on some input data, which can be labeled or unlabeled, your algorithm will produce an estimate about a pattern in the data.
- An Error Function: An error function evaluates the prediction of the model. If there are known examples, an error function can make a comparison to assess the accuracy of the model.
- A Model Optimization Process: If the model can fit better to the data points in the training set, then weights are adjusted to reduce the discrepancy between the known example and the model estimate. The algorithm will repeat this iterative “evaluate and optimize” process, updating weights autonomously until a threshold of accuracy has been met.
Machine learning versus deep learning versus neural networks
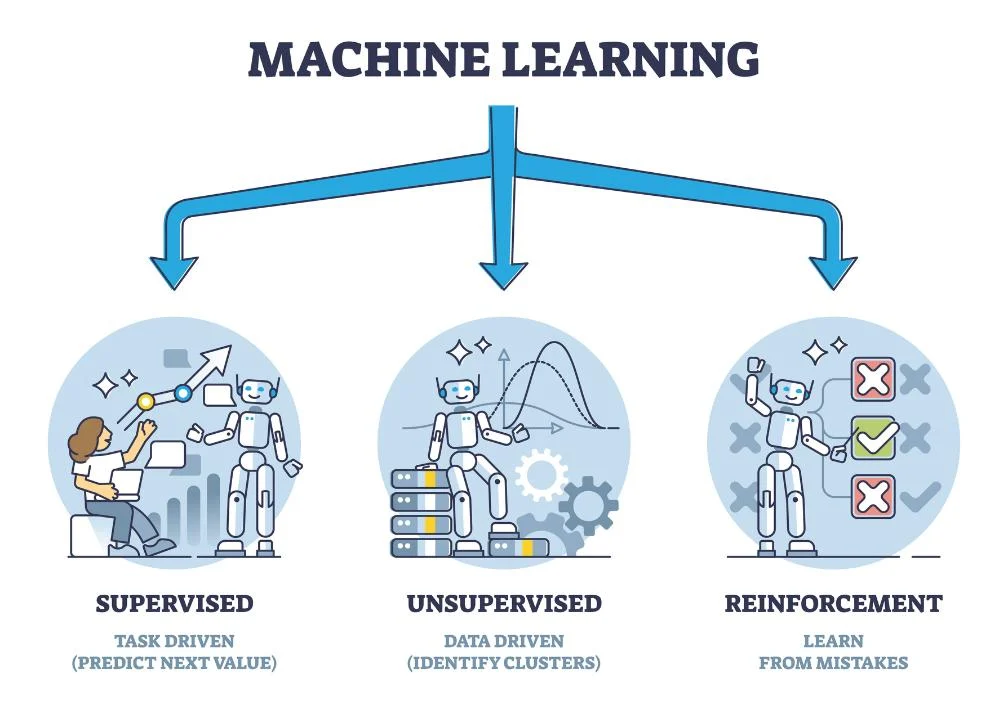
Since deep learning and machine learning tend to be used interchangeably, it’s worth noting the nuances between the two. Machine learning, deep learning, and neural networks are all sub-fields of artificial intelligence. However, neural networks is actually a sub-field of machine learning, and deep learning is a sub-field of neural networks.The way in which deep learning and machine learning differ is in how each algorithm learns. “Deep” machine learning can use labeled datasets, also known as supervised learning, to inform its algorithm, but it doesn’t necessarily require a labeled dataset. The deep learning process can ingest unstructured data in its raw form (e.g., text or images), and it can automatically determine the set of features which distinguish different categories of data from one another. This eliminates some of the human intervention required and enables the use of large amounts of dataClassical, or “non-deep,” machine learning is more dependent on human intervention to learn. Human experts determine the set of features to understand the differences between data inputs, usually requiring more structured data to learn.Neural networks, or artificial neural networks (ANNs), are comprised of node layers, containing an input layer, one or more hidden layers, and an output layer. Each node, or artificial neuron, connects to another and has an associated weight and threshold. If the output of any individual node is above the specified threshold value, that node is activated, sending data to the next layer of the network. Otherwise, no data is passed along to the next layer of the network by that node. The “deep” in deep learning is just referring to the number of layers in a neural network. A neural network that consists of more than three layers—which would be inclusive of the input and the output—can be considered a deep learning algorithm or a deep neural network. A neural network that only has three layers is just a basic neural network.Deep learning and neural networks are credited with accelerating progress in areas such as computer vision, natural language processing, and speech recognigeMachine learning models fall into three primary categories. Supervised learning, also known as supervised machine learning, is defined by its use of labeled datasets to train algorithms to classify data or predict outcomes accurately. As input data is fed into the model, the model adjusts its weights until it has been fitted appropriately. This occurs as part of the cross validation process to ensure that the model avoids overfitting or underfitting. Supervised learning helps organizations solve a variety of real-world problems at scale, such as classifying spam in a separate folder from your inbox. Some methods used in supervised learning include neural networks, naïve bayes, linear regression, logistic regression, random forest, and support vector machine (SVM).Machine learning models fall into three primary categories.Unsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyze and cluster unlabeled datasets (subsets called clusters). These algorithms discover hidden patterns or data groupings without the need for human intervention. This method’s ability to discover similarities and differences in information make it ideal for exploratory data analysis, cross-selling strategies, customer segmentation, and image and pattern recognition. It’s also used to reduce the number of features in a model through the process of dimensionality reduction. Principal component analysis (PCA) and singular value decomposition (SVD) are two common approaches for this. Other algorithms used in unsupervised learning include neural networks, k-means clustering, and probabilistic clustering methods.

unsupervised
Unsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyze and cluster unlabeled datasets (subsets called clusters). These algorithms discover hidden patterns or data groupings without the need for human intervention. This method’s ability to discover similarities and differences in information make it ideal for exploratory data analysis, cross-selling strategies, customer segmentation, and image and pattern recognition. It’s also used to reduce the number of features in a model through the process of dimensionality reduction. Principal component analysis (PCA) and singular value decomposition (SVD) are two common approaches for this. Other algorithms used in unsupervised learning include neural networks, k-means clustering, and probabilistic clustering methods.
Semi-supervised learning
Semi-supervised learning offers a happy medium between supervised and unsupervised learning. During training, it uses a smaller labeled data set to guide classification and feature extraction from a larger, unlabeled data set. Semi-supervised learning can solve the problem of not having enough labeled data for a supervised learning algorithm. It also helps if it’s too costly to label enough data.
For a deep dive into the differences between these approaches, check out “Supervised vs. Unsupervised Learning: What’s the Difference
Reinforcement machine learning
Reinforcement machine learning is a machine learning model that is similar to supervised learning, but the algorithm isn’t trained using sample data. This model learns as it goes by using trial and error. A sequence of successful outcomes will be reinforced to develop the best recommendation or policy for a given problem.
The IBM Watson® system that won the Jeopardy! challenge in 2011 is a good example. The system used reinforcement learning to learn when to attempt an answer (or question, as it were), which square to select on the board, and how much to wager—especially on daily doubles.
Learn more about reinforcement learning
Advantages and disadvantages of machine learning algorithms
Depending on your budget, need for speed and precision required, each algorithm type—supervised, unsupervised, semi-supervised, or reinforcement—has its own advantages and disadvantages. For example, decision tree algorithms are used for both predicting numerical values (regression problems) and classifying data into categories. Decision trees use a branching sequence of linked decisions that may be represented with a tree diagram. A prime advantage of decision trees is that they are easier to validate and audit than a neural network. The bad news is that they can be more unstable than other decision predictors.
Overall, there are many advantages to machine learning that businesses can leverage for new efficiencies. These include machine learning identifying patterns and trends in massive volumes of data that humans might not spot at all. And this analysis requires little human intervention: just feed in the dataset of interest and let the machine learning system assemble and refine its own algorithms—which will continually improve with more data input over time. Customers and users can enjoy a more personalized experience as the model learns more with every experience with that person.
On the downside, machine learning requires large training datasets that are accurate and unbiased. GIGO is the operative factor: garbage in / garbage out. Gathering sufficient data and having a system robust enough to run it might also be a drain on resources. Machine learning can also be prone to error, depending on the input. With too small a sample, the system could produce a perfectly logical algorithm that is completely wrong or misleading. To avoid wasting budget or displeasing customers, organizations should act on the answers only when there is high confidence in the output.
Challenges of machine learning
As machine learning technology has developed, it has certainly made our lives easier. However, implementing machine learning in businesses has also raised a number of ethical concerns about AI technologies. Some of these include:
Technological singularity
While this topic garners a lot of public attention, many researchers are not concerned with the idea of AI surpassing human intelligence in the near future. Technological singularity is also referred to as strong AI or superintelligence. Philosopher Nick Bostrum defines superintelligence as “any intellect that vastly outperforms the best human brains in practically every field, including scientific creativity, general wisdom, and social skills.” Despite the fact that superintelligence is not imminent in society, the idea of it raises some interesting questions as we consider the use of autonomous systems, like self-driving cars. It’s unrealistic to think that a driverless car would never have an accident, but who is responsible and liable under those circumstances? Should we still develop autonomous vehicles, or do we limit this technology to semi-autonomous vehicles which help people drive safely? The jury is still out on this, but these are the types of ethical debates that are occurring as new, innovative AI technology develops.
AI impact on jobs
While a lot of public perception of artificial intelligence centers around job losses, this concern should probably be reframed. With every disruptive, new technology, we see that the market demand for specific job roles shifts. For example, when we look at the automotive industry, many manufacturers, like GM, are shifting to focus on electric vehicle production to align with green initiatives. The energy industry isn’t going away, but the source of energy is shifting from a fuel economy to an electric one.
In a similar way, artificial intelligence will shift the demand for jobs to other areas. There will need to be individuals to help manage AI systems. There will still need to be people to address more complex problems within the industries that are most likely to be affected by job demand shifts, such as customer service. The biggest challenge with artificial intelligence and its effect on the job market will be helping people to transition to new roles that are in demand.
Privacy
Privacy tends to be discussed in the context of data privacy, data protection, and data security. These concerns have allowed policymakers to make more strides in recent years. For example, in 2016, GDPR legislation was created to protect the personal data of people in the European Union and European Economic Area, giving individuals more control of their data. In the United States, individual states are developing policies, such as the California Consumer Privacy Act (CCPA), which was introduced in 2018 and requires businesses to inform consumers about the collection of their data. Legislation such as this has forced companies to rethink how they store and use personally identifiable information (PII). As a result, investments in security have become an increasing priority for businesses as they seek to eliminate any vulnerabilities and opportunities for surveillance, hacking, and cyberattacks.

Bias and discrimination
Instances of bias and discrimination across a number of machine learning systems have raised many ethical questions regarding the use of artificial intelligence. How can we safeguard against bias and discrimination when the training data itself may be generated by biased human processes? While companies typically have good intentions for their automation efforts, Reuters (link resides outside ibm.com) highlights some of the unforeseen consequences of incorporating AI into hiring practices. In their effort to automate and simplify a process, Amazon unintentionally discriminated against job candidates by gender for technical roles, and the company ultimately had to scrap the project. Harvard Business Review (link resides outside ibm.com) has raised other pointed questions about the use of AI in hiring practices, such as what data you should be able to use when evaluating a candidate for a role.
Bias and discrimination aren’t limited to the human resources function either; they can be found in a number of applications from facial recognition software to social media algorithms.
As businesses become more aware of the risks with AI, they’ve also become more active in this discussion around AI ethics and values. For example, IBM has sunset its general purpose facial recognition and analysis products. IBM CEO Arvind Krishna wrote: “IBM firmly opposes and will not condone uses of any technology, including facial recognition technology offered by other vendors, for mass surveillance, racial profiling, violations of basic human rights and freedoms, or any purpose which is not consistent with our values and Principles of Trust and Transparency.”
Accountability
Since there isn’t significant legislation to regulate AI practices, there is no real enforcement mechanism to ensure that ethical AI is practiced. The current incentives for companies to be ethical are the negative repercussions of an unethical AI system on the bottom line. To fill the gap, ethical frameworks have emerged as part of a collaboration between ethicists and researchers to govern the construction and distribution of AI models within society. However, at the moment, these only serve to guide. Some research (link resides outside ibm.com) shows that the combination of distributed responsibility and a lack of foresight into potential consequences aren’t conducive to preventing harm to society.
Machine Learning Business Goal: Model Customer Lifetime Value
Customer lifetime value modeling is essential for ecommerce businesses but is also applicable across many other industries. In this model, organizations use machine learning algorithms to identify, understand, and retain their most valuable customers. These value models evaluate massive amounts of customer data to determine the biggest spenders, the most loyal advocates for a brand, or combinations of these types of qualities.
Customer lifetime value models are especially effective at predicting the future revenue that an individual customer will bring to a business in a given period. This information empowers organizations to focus marketing efforts on encouraging high-value customers to interact with their brand more often. Customer lifetime value models also help organizations target their acquisition spend to attract new customers that are similar to existing high-value customers.
Model Customer Churn Through Machine Learning
Acquiring new customers is more time consuming and costlier than keeping existing customers satisfied and loyal. Customer churn modeling helps organizations identify which customers are likely to stop engaging with a business—and why.
An effective churn model uses machine learning algorithms to provide insight into everything from churn risk scores for individual customers to churn drivers, ranked by importance. These outputs are key to developing an algorithmic retention strategy.
Gaining deeper insight into customer churn helps businesses optimize discount offers, email campaigns, and other targeted marketing initiatives that keep their high-value customers buying—and coming back for more.
Consumers have more choices than ever, and they can compare prices via a wide range of channels, instantly. Dynamic pricing, also known as demand pricing, enables businesses to keep pace with accelerating market dynamics. It lets organizations flexibly price items based on factors including the level of interest of the target customer, demand at the time of purchase, and whether the customer has engaged with a marketing campaign.
This level of business agility requires a solid machine learning strategy and a great deal of data about how different customers’ willingness to pay for a good or service changes across a variety of situations. Although dynamic pricing models can be complex, companies such as airlines and ride-share services have successfully implemented dynamic price optimization strategies to maximize revenue.
Machine Learning Business Goal: Target Customers with Customer Segmentation
Successful marketing has always been about offering the right product to the right person at the right time. Not so long ago, marketers relied on their own intuition for customer segmentation, separating customers into groups for targeted campaigns.
Today, machine learning enables data scientists to use clustering and classification algorithms to group customers into personas based on specific variations. These personas consider customer differences across multiple dimensions such as demographics, browsing behavior, and affinity. Connecting these traits to patterns of purchasing behavior enables data-savvy companies to roll out highly personalized marketing campaigns that are more effective at boosting sales than generalized campaigns are.
As the data available to businesses grows and algorithms become more sophisticated, personalization capabilities will increase, moving businesses closer to the ideal customer segment of one.



Leave feedback about this